Waymo just published a blog post and paper describing how it tested imitation learning for path planning, something that Tesla has recently been reported. Waymo trained a path planning neural network to handle a few driving tasks using 1) imitation of 1,440 hours of human driving and 2) simulation. The path planning network, ChauffeurNet, was able to stop for a stop sign, stop for a yellow light, nudge around a parked car, and follow other cars while maintaining the flow of traffic.
It’s important to understand this is not end to end learning (sometimes called “behaviour cloning”):
The “mid-level representations” are the metadata, like the bounding boxes, labels, and location and motion estimates you see in verygreen’s “What Autopilot sees” videos. The perception neural network does its thing, and then outputs abstract information (not raw pixel information) to the path planning neural network.
It’s also important to understand Waymo only used supervised learning, not reinforcement learning:
In the paper, Waymo says that ChauffeurNet performs worse than Waymo’s current path planning system, which uses a combination of machine learning and hand-coded rules. However, they also say that there is room to build on this approach:
It’s important to understand this is not end to end learning (sometimes called “behaviour cloning”):
“In order to drive by imitating an expert, we created a deep recurrent neural network (RNN) named ChauffeurNet that is trained to emit a driving trajectory by observing a mid-level representation of the scene as an input. A mid-level representation does not directly use raw sensor data, thereby factoring out the perception task, and allows us to combine real and simulated data for easier transfer learning.”
The “mid-level representations” are the metadata, like the bounding boxes, labels, and location and motion estimates you see in verygreen’s “What Autopilot sees” videos. The perception neural network does its thing, and then outputs abstract information (not raw pixel information) to the path planning neural network.
It’s also important to understand Waymo only used supervised learning, not reinforcement learning:
“Beyond our approach, extensive simulations of highly interactive or rare situations may be performed, accompanied by a tuning of the driving policy using reinforcement learning (RL). However, doing RL requires that we accurately model the real-world behavior of other agents in the environment, including other vehicles, pedestrians, and cyclists. For this reason, we focus on a purely supervised learning approach in the present work, keeping in mind that our model can be used to create naturally-behaving “smart-agents” for bootstrapping RL.”
In the paper, Waymo says that ChauffeurNet performs worse than Waymo’s current path planning system, which uses a combination of machine learning and hand-coded rules. However, they also say that there is room to build on this approach:
“...the model is not yet fully competitive with motion planning approaches but we feel that this is a good step forward for machine learned driving models. There is room for improvement: comparing to end-to-end approaches, and investigating alternatives to imitation dropout are among them. But most importantly, we believe that augmenting the expert demonstrations with a thorough exploration of rare and difficult scenarios in simulation, perhaps within a reinforcement learning framework, will be the key to improving the performance of these models especially for highly interactive scenarios.”
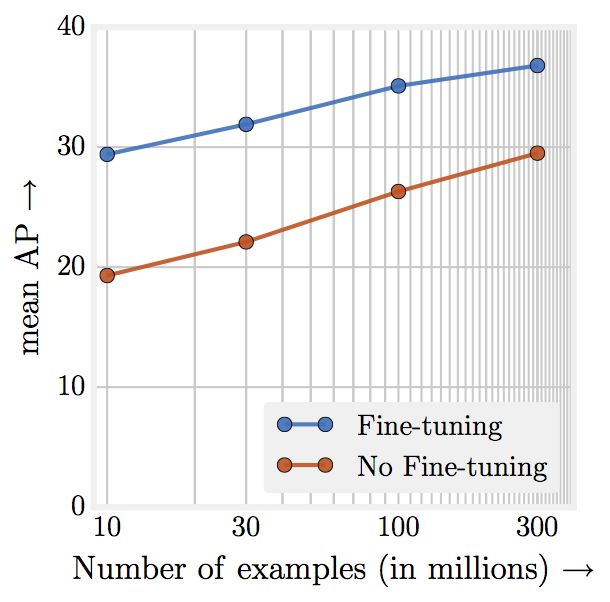
If my interpretation of Amir Efrati’s reporting in The Information is correct, Tesla is testing (or perhaps even using in production today, who knows) an imitation learning approach to path planning. What’s most exciting there is Tesla has the capacity to collect so much more metadata (a.k.a. mid-level representations) on human driving. Even if Waymo’s average speed over those 1,440 hours was 90 mph (an unrealistically high estimate), that’s only a total of about 130,000 miles. Tesla has around 300,000 HW2 cars on the road. The average U.S. driver drives around 1,000 miles per month. So HW2 Teslas are probably driving around 300 million miles per month. This means Tesla has an ocean of data to collect from. It would be feasible for Tesla to collect billions of miles of data if that would be useful. Tesla could collect four orders of magnitude more data than Waymo used for ChauffeurNet.