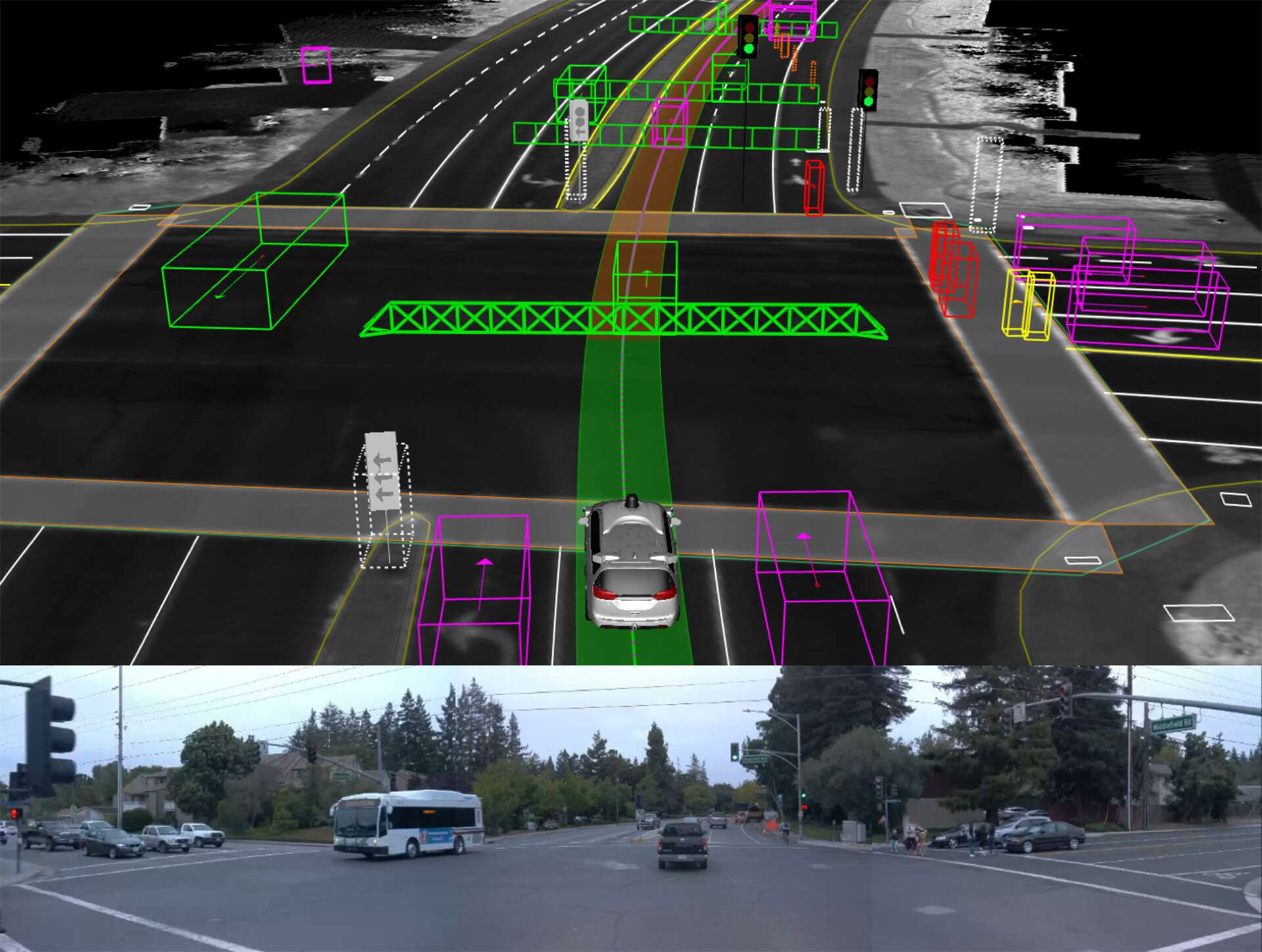
Not true. While in Las Vegas last month I rode is a self-driving Lyft car (made by Aptiv). It uses only lidar & radar. No cameras, no ultrasonics. I took 6 different autonomous rides, in 6 different cars, during my week out there. It drove perfectly, 100 times better than any Tesla. It handled jay walkers, merging, red lights, left turns, being cut off, etc. I suggest everyone who is interested in this sort of thing should try it next time you are in Vegas. Just use your normal Lyft app.
p.s. They can get away with no cameras because Las Vegas is a "smart city" and the traffic light status (red light, green light) is computerized and the car can poll the status remotely. I seem to recall being told that most signal lights out there also have a radio transmitter that broadcasts the signal's ID# as well as its current status. The cars use high-def map data and know where all the limit lines are and where all the lane lines are, and which lanes are turn-only lanes, etc.