Like I said they are still in the bringup phase for it which explains the extra debug.Did this image happen to come from a development/beta vehicle? Some of the kernel debug parameters make sense in a production environment, but others really only make sense during development because of the potential negative performance impact.



Welcome to Tesla Motors Club
Discuss Tesla's Model S, Model 3, Model X, Model Y, Cybertruck, Roadster and More.
Register
Install the app
How to install the app on iOS
You can install our site as a web app on your iOS device by utilizing the Add to Home Screen feature in Safari. Please see this thread for more details on this.
Note: This feature may not be available in some browsers.
-
Want to remove ads? Register an account and login to see fewer ads, and become a Supporting Member to remove almost all ads.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Tesla autopilot HW3
- Thread starter verygreen
- Start date
yes, there are (of hw2.5) https://photos.app.goo.gl/7w6LQlQrxjhISILY2Does anybody have detailed, high-res photos of the HW2.5 and/or HW3 boards?
they have some deserializers that are connected to the cameras and then get that stuff via .... csi?
Last edited:
yes, there are https://photos.app.goo.gl/7w6LQlQrxjhISILY2
they have some deserializers that are connected to the cameras and then get that stuff via .... csi?
Those look a lot like the photos featured on Electrek last year. Sadly, the clearest components are the GPS, memory, and GPUs. Either way, the A53/A72 based SoCs I've found all have CSI available natively, so that probably makes the most sense. CSI is also enabled in the kernel config file, which really wouldn't make much sense unless you had those capabilities and were using them.
yeah, I guess I can take more detailed ones but there's little point at this stage and there were some Chinese reports but the pictures were all downsampled, though all components were actually listed.Those look a lot like the photos featured on Electrek last year. Sadly, the clearest components are the GPS, memory, and GPUs. Either way, the A53/A72 based SoCs I've found all have CSI available natively, so that probably makes the most sense. CSI is also enabled in the kernel config file, which really wouldn't make much sense unless you had those capabilities and were using them.
Only tesla has hw3 samples at this stage I imagine, and I somehow doubt they are sharing
")
Anyway, feel free to ask your kernel questions here or in a PM, but keep in mind I only have hw3 code, but nowhere to run it. I obviously have hw2.5 hw so a lot more is possible there (but again very little is unknown about it at this time)
P.S.: Let us hope the new HW3 is also "radar agnostic", as that old junk [which infamously cannot distinguish a stopped fire-truck in the planned path from roadside clutter at highway speeds] is certainly long overdue an upgrade too.
This isn't a limitation of the radar sensors used, but rather in how radar works and must be implemented in a car. First, the car uses doppler radar, so it uses a difference of speed to "see" objects. Second, all still objects effectively "look" the same to the radar sensor. So, passing a road sign looks like a giant flat reflection, and the system would want to filter it out. Likewise, a stopped truck basically blends into the surroundings and gets filtered out.
Something to note is that every vehicle using radar-based EAB has the exact same problem. If someone changes lanes quickly in front of you to avoid a stationary object, you're going to hit that object.
That said, I do feel that a system relying so heavily on vision will quickly find the camera sensor data becoming the limiting factor. It would be amazing if they could swap sensors easily, even if it was just the trifocal cluster in the front. Higher resolution could mean the recognizing a vehicle in your path seconds earlier. At 60mph, that could be ~200 feet.
Remember that as the photosites in a sensor get smaller and pixel density increases, electrical noise becomes a bigger and bigger problem. So doubling the resolution on a camera isn't necessarily going to give you double the usable data for the network. Further making things complex, a camera working at a high frame rate with a high resolution is going to produce an image that requires more pixels to be processed, which will require more RAM, faster busses, and bigger networks. Most existing neural nets I've seen do an unbelievable job at detecting objects and accurately classifying them on super low resolution images.
At 100 MPH, a vehicle would travel 147 feet per second. With a camera operating at 60 fps, capturing two frames for motion estimation, the object in the camera would travel around 9.7 feet. If the object is 100-200 feet away, it's not too big a deal. At 300 feet per second, that object travels 20 feet in the same 2-frame span. There aren't too many situations in which two vehicle approach one another with a speed difference of 300 feet per second, so that would be a pretty rare case. But even still, with the object covering only 20 feet of distance, the system could have worked out what it is, where it is, where it's headed, and how fast it's getting there.
At distances beyond 100-300 feet, you're probably wisest to rely on lidar or optical cameras with optics on them that are optimized for distance. This requires no increase of resolution, and would actually reduce the field of view anyway.
how do you arrive at 7880? Also there are 3 cpu clusters of 4 cores mentioned, but does that rally mean 12 cores? I don't deal with DTs often so I don't really know.
This kind of makes no sense. Camera sensor determines the dynamic range, not the unit that receives the results, no?
I think reference to single exposure is the key and it means that ISP can combine two frames taken at different exposure, like HDR photos on the smartphone.
MarkS22
Member
This isn't a limitation of the radar sensors used, but rather in how radar works and must be implemented in a car. First, the car uses doppler radar, so it uses a difference of speed to "see" objects. Second, all still objects effectively "look" the same to the radar sensor. So, passing a road sign looks like a giant flat reflection, and the system would want to filter it out. Likewise, a stopped truck basically blends into the surroundings and gets filtered out.
Something to note is that every vehicle using radar-based EAB has the exact same problem. If someone changes lanes quickly in front of you to avoid a stationary object, you're going to hit that object.
Remember that as the photosites in a sensor get smaller and pixel density increases, electrical noise becomes a bigger and bigger problem. So doubling the resolution on a camera isn't necessarily going to give you double the usable data for the network. Further making things complex, a camera working at a high frame rate with a high resolution is going to produce an image that requires more pixels to be processed, which will require more RAM, faster busses, and bigger networks. Most existing neural nets I've seen do an unbelievable job at detecting objects and accurately classifying them on super low resolution images.
At 100 MPH, a vehicle would travel 147 feet per second. With a camera operating at 60 fps, capturing two frames for motion estimation, the object in the camera would travel around 9.7 feet. If the object is 100-200 feet away, it's not too big a deal. At 300 feet per second, that object travels 20 feet in the same 2-frame span. There aren't too many situations in which two vehicle approach one another with a speed difference of 300 feet per second, so that would be a pretty rare case. But even still, with the object covering only 20 feet of distance, the system could have worked out what it is, where it is, where it's headed, and how fast it's getting there.
At distances beyond 100-300 feet, you're probably wisest to rely on lidar or optical cameras with optics on them that are optimized for distance. This requires no increase of resolution, and would actually reduce the field of view anyway.
While this is generally true (i.e. more pixels mean more noise, less light gathering), that ignores the fact sensor technology is improving dramatically. Advancements like back-illumination can offset some of these disadvantages.
For now, the optical trifocal cluster seems to be compensating for resolution. But at a certain point, the quality and cost of vastly superior sensors will be available. I’m curious if the wiring is designed to handle this to make a hypothetical HW4.0 sensor suite possible if needed. We know they can swap out the processors easily. Will the dead end be sensors?
But the camera sensors they use already have "HDR mode" where they give you 10 bits of data which is aplenty as we saw from the raw images even with a lot of contrast (like traffic light with sun directly behind it).I think reference to single exposure is the key and it means that ISP can combine two frames taken at different exposure, like HDR photos on the smartphone.
Combining two pictures in a moving vehicle makes even less sense due to potentially huge movement between the frames.
MarkS22
Member
But the camera sensors they use already have "HDR mode" where they give you 10 bits of data which is aplenty as we saw from the raw images even with a lot of contrast (like traffic light with sun directly behind it).
Combining two pictures in a moving vehicle makes even less sense due to potentially huge movement between the frames.
Most likely for spatial reconstruction, no? Seems like a good way to use a 2D source to generate 3D data.
yes, but not for "HDR"-like dynamic range boost.Most likely for spatial reconstruction, no? Seems like a good way to use a 2D source to generate 3D data.
MarkS22
Member
yes, but not for "HDR"-like dynamic range boost.
Right. I meant it’s much more likely being used for 3D solving than HDR.
They’d be better off putting an ND filter on one of the three forward cameras to add to dynamic range if it became a major issue.
While this is generally true (i.e. more pixels mean more noise, less light gathering), that ignores the fact sensor technology is improving dramatically. Advancements like back-illumination can offset some of these disadvantages.
For now, the optical trifocal cluster seems to be compensating for resolution. But at a certain point, the quality and cost of vastly superior sensors will be available. I’m curious if the wiring is designed to handle this to make a hypothetical HW4.0 sensor suite possible if needed. We know they can swap out the processors easily. Will the dead end be sensors?
Or they could use the less expensive cameras to increase margins that much more. Again, given more data you will require more processing, and more of that processing will be done on useless data (areas of the image that don't contain important or meaningful objects). We already "know" Tesla is downsampling the images they gather today to limit processing requirements, so I don't see much use in going further for such a minimal gain of functionality.
Anyway, the cabling for the cameras is likely just coaxial given what the connectors look like. They could be carrying LVDS, GMSL, or even Ethernet. We know nVidia uses GMSL on their boards, and we know Continental's components use Ethernet or LVDS. GMSL does 1.5 or 3Gbit/sec, Ethernet obviously can be 100M, 1G, 2.5G, 5G, 10G, or 25Gbit/sec, and LVDS is really less of a particular signalling rate rather than a PHY signalling method, but lots of LVDS devices communicate at 655M, 1G, and 3Gbit/sec. No matter what, swapping the camera and MCU at the same time could mean any future protocol and speed could be used as long as the cabling is shielded and can handle the signalling rate. Like moving from 10Mbit to 100Mbit to 1000Mbit to 10000Mbit Ethernet on the same Cat-6 cable.
MarkS22
Member
Or they could use the less expensive cameras to increase margins that much more. Again, given more data you will require more processing, and more of that processing will be done on useless data (areas of the image that don't contain important or meaningful objects). We already "know" Tesla is downsampling the images they gather today to limit processing requirements, so I don't see much use in going further for such a minimal gain of functionality.
Anyway, the cabling for the cameras is likely just coaxial given what the connectors look like. They could be carrying LVDS, GMSL, or even Ethernet. We know nVidia uses GMSL on their boards, and we know Continental's components use Ethernet or LVDS. GMSL does 1.5 or 3Gbit/sec, Ethernet obviously can be 100M, 1G, 2.5G, 5G, 10G, or 25Gbit/sec, and LVDS is really less of a particular signalling rate rather than a PHY signalling method, but lots of LVDS devices communicate at 655M, 1G, and 3Gbit/sec. No matter what, swapping the camera and MCU at the same time could mean any future protocol and speed could be used as long as the cabling is shielded and can handle the signalling rate. Like moving from 10Mbit to 100Mbit to 1000Mbit to 10000Mbit Ethernet on the same Cat-6 cable.
Resolution, sure. But you can still have better images without more data. Dynamic range, low-light sensitivity, and color come to mind. Just like the difference between AP2.0 and 2.5.
While I understand your point of keeping it cheap and simple, there will certainly be a time (HW4?) where camera data will be the limiting factor of neural network recognizing objects faster and more accurately. And, by that time, I wouldn’t be surprised if better sensors cost less than the current ones.
That said, coax should be pretty future-proof. I appreciate that insight. Are there photos of the connectors on the cameras anywhere?
lunitiks
Cool James & Black Teacher
They are coax cables yes. Rosenberger fakra connectors.
APE2.0 unit:

APE2.0 unit:
lunitiks
Cool James & Black Teacher
lunitiks
Cool James & Black Teacher
According to Tesla's wiring diagram, the b-pillar and side repeater cams (and gps!) are wired with D302. I believe this means it's a LEONI Dacar 302, 0.4 mm2 coax. You can tell Tesla uses Dacar 535 for the backup cam, ref. the picture above.
The three forward cameras are wired with RG316 according to the schematics. Dunno what brand
The three forward cameras are wired with RG316 according to the schematics. Dunno what brand
Last edited:
electronblue
Active Member
How did you conclude it was an Exynos SoC? There is no Exynos SoC with the Cortex A72 core.
Are you sure you are not seeing some kind of leftover files for an old prototyping board?
Also, there will be other shiny new things in the HW3 that will boost the performance of the NN, alongside with the camera agnostic architecture you were mentioning.
Source: *wink* *wink*
Okay so something I think others here missed. Did Exynos 7650 and 7800 with A72 core actually come out or were they just leaked or announced in 2015? When Tesla would have gotten prototypes. But did those come to the market? There is precious little on them online after the 2015 preliminary info. @verygreen
Because all this from Tesla aka @shiny.sky.00 would fit with Tesla prototyping on 7650/7800 but then plans changing and them going somewhere else for the SoC. Which would indeed point to the here analyzed AP 2.5 firmware having leftovers from a prototype board.
Then again all this would also with with @shiny.sky.00 just being a troll with poor googling skills.
Anyway great job by @verygreen and co so thank you for that.
Last edited:
jimmysanto
New Member




@verygreen the text on the attached images are too blurry. Is a higher resolution version available? Thanks!
Without reading the post at all and only looking at just the picture. i just wanted to say that non-stacked convolution layers is pretty standard in the world of CNN nowadays, it all started with the first inception network from google which Google really showed that you don't have to just stack conv layers with pooling, drops, on top of each other, but that you can get clever with it. That and using smaller conv filters there is nothing mind blowing about it today. its pretty standard.
Here is Inception v1 from 2014
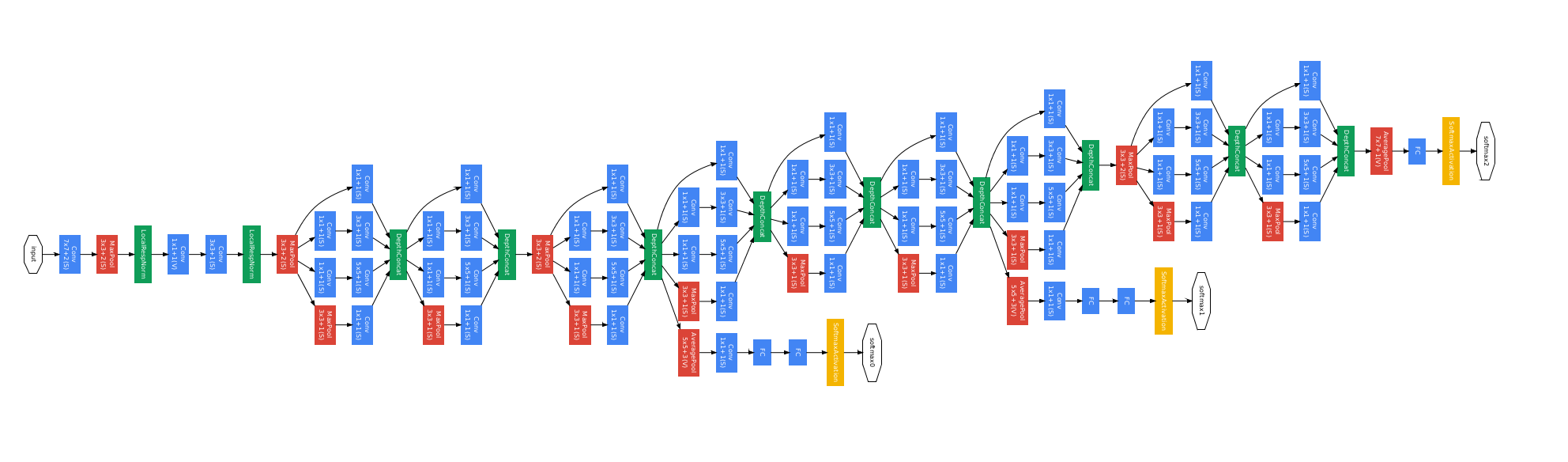
EDIT: After reading the post. My comments doesn't change. Only thing i would add is that I'm surprised people still take anything jimmy_d says seriously.
I gave you a disagree alone for posting to a thread without reading its opening post - if you just want to demonstrate your knowledge on this topic without discussing other posts, you are free to create your own thread.
Anyway, the cabling for the cameras is likely just coaxial given what the connectors look like. They could be carrying LVDS, GMSL, or even Ethernet. We know nVidia uses GMSL on their boards, and we know Continental's components use Ethernet or LVDS. GMSL does 1.5 or 3Gbit/sec, Ethernet obviously can be 100M, 1G, 2.5G, 5G, 10G, or 25Gbit/sec, and LVDS is really less of a particular signalling rate rather than a PHY signalling method, but lots of LVDS devices communicate at 655M, 1G, and 3Gbit/sec. No matter what, swapping the camera and MCU at the same time could mean any future protocol and speed could be used as long as the cabling is shielded and can handle the signalling rate. Like moving from 10Mbit to 100Mbit to 1000Mbit to 10000Mbit Ethernet on the same Cat-6 cable.
LVDS according to this:
从TeslaAP2.0/2.5运算单元看未来无人驾驶域控制器的设计趋势 | 雷锋网
Similar threads
- Replies
- 3
- Views
- 671
- Article
- Replies
- 4
- Views
- 2K
- Replies
- 128
- Views
- 10K
- Replies
- 17
- Views
- 7K
- Replies
- 25
- Views
- 1K