> Clear-to-go boost through turns on minor-to-major roads (plan to expland to all roads in v9.3)
Accelerates faster during turns.
> Improved peek behavior where we are smarter about when to go around the lead vehicle by reasoning about the causes for lead vehicle being slow.
When is peak? When it is needed most? Right before a decision is needed to be made?
> v1 of the multi-modal predictions for where other vehicles (are) expected to drive. Partial implementation
Multi-model means multiple modes. FSD will have predictions for different possibilities what a car will do. For example: 70% chance will continue, 20% chance will turn, 10% will stop. Multi-model may mean that the algorithm used depends upon the situation. For example if near an intersection.
> New lanes network with 50k more clips (almost double) from the new auto-labeling pipeline.
More lanes mapped? Is this a right turn lane, a bike lane, etc...
> New VRU velocity model with 12% improvement to velocity and better VRU clear-to-go performance.
VRU = vulnerable road user. Pedestrian, bike, escooter, etc... Thanks to Daniel in SD for that.
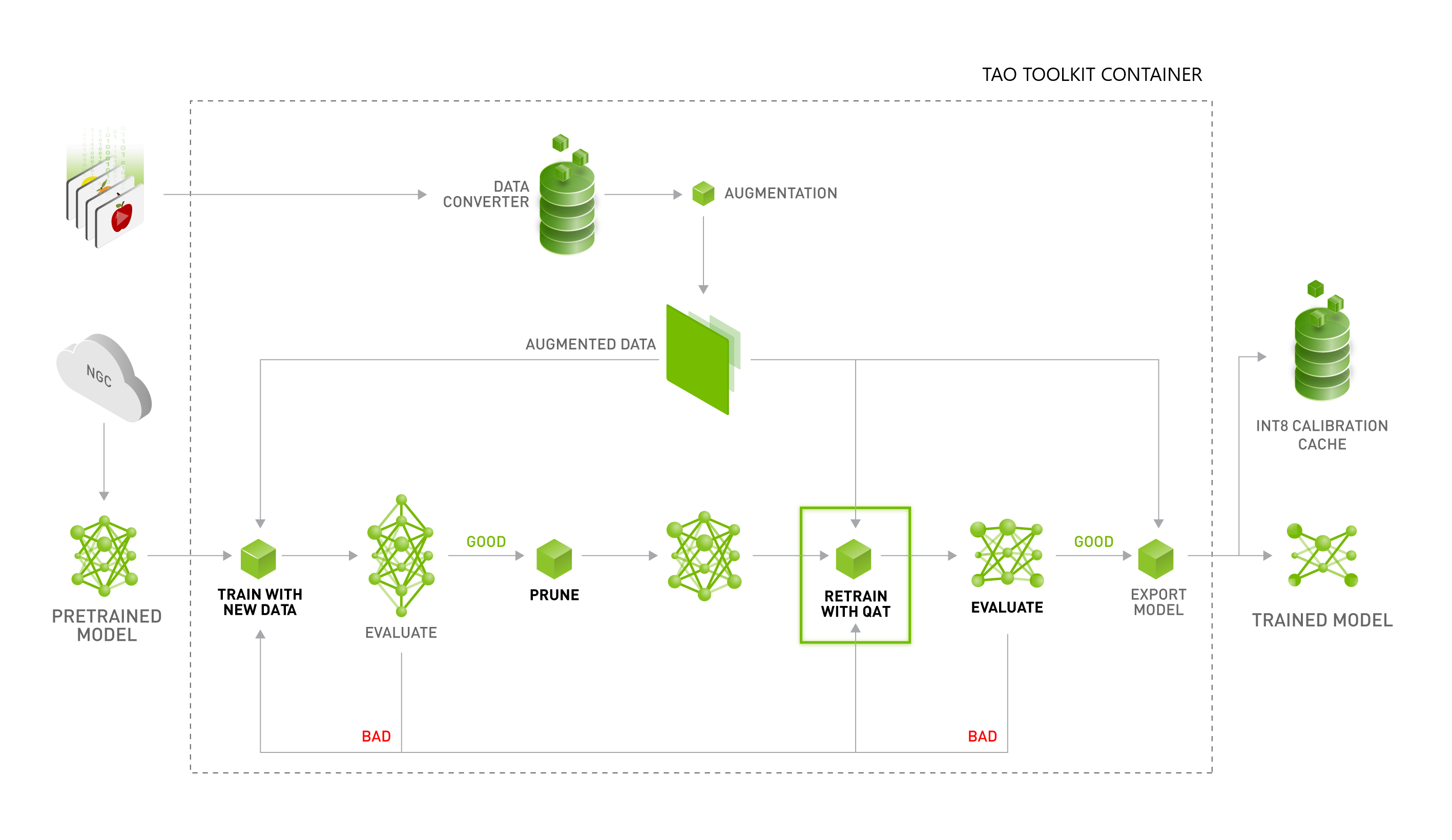
> Model trained with "Quantization-aware-training" (QAR), an improved technique to mitigate int8 quantization.
int8 quantization is used during machine learning training. Initially floating point was used, but to conserve memory a switch was made to int8. This introduces rounding errors. QAR is a technique used to take into account the rounding error, and provide better overall performance.
> Enabled inter-soc synchronous compute scheduling between vision and vector space processes.
They have a new task scheduler that is synchronous based. In other words, discrete time blocks are allocated for computer vision and vector computation.
> Planner in the loop is happening in v10.
The planner is what FSD is going to do. "in the loop" suggest this will be given a discrete amount of time to compute also. This is compared to an unbounded amount of time to compute and interrupted as needed by the task/process scheduler.
> Shadow mode for new crossing/merging targets network which will help improve VRU control.
There is a new algorithm being tested for VRU prediction for pedestrians, bikes, e-scooters, etc that are crossing in the cars path or merging.
Accelerates faster during turns.
> Improved peek behavior where we are smarter about when to go around the lead vehicle by reasoning about the causes for lead vehicle being slow.
When is peak? When it is needed most? Right before a decision is needed to be made?
> v1 of the multi-modal predictions for where other vehicles (are) expected to drive. Partial implementation
Multi-model means multiple modes. FSD will have predictions for different possibilities what a car will do. For example: 70% chance will continue, 20% chance will turn, 10% will stop. Multi-model may mean that the algorithm used depends upon the situation. For example if near an intersection.
> New lanes network with 50k more clips (almost double) from the new auto-labeling pipeline.
More lanes mapped? Is this a right turn lane, a bike lane, etc...
> New VRU velocity model with 12% improvement to velocity and better VRU clear-to-go performance.
VRU = vulnerable road user. Pedestrian, bike, escooter, etc... Thanks to Daniel in SD for that.
> Model trained with "Quantization-aware-training" (QAR), an improved technique to mitigate int8 quantization.
int8 quantization is used during machine learning training. Initially floating point was used, but to conserve memory a switch was made to int8. This introduces rounding errors. QAR is a technique used to take into account the rounding error, and provide better overall performance.
> Enabled inter-soc synchronous compute scheduling between vision and vector space processes.
They have a new task scheduler that is synchronous based. In other words, discrete time blocks are allocated for computer vision and vector computation.
> Planner in the loop is happening in v10.
The planner is what FSD is going to do. "in the loop" suggest this will be given a discrete amount of time to compute also. This is compared to an unbounded amount of time to compute and interrupted as needed by the task/process scheduler.
> Shadow mode for new crossing/merging targets network which will help improve VRU control.
There is a new algorithm being tested for VRU prediction for pedestrians, bikes, e-scooters, etc that are crossing in the cars path or merging.
Last edited: