Daniel in SD
(supervised)
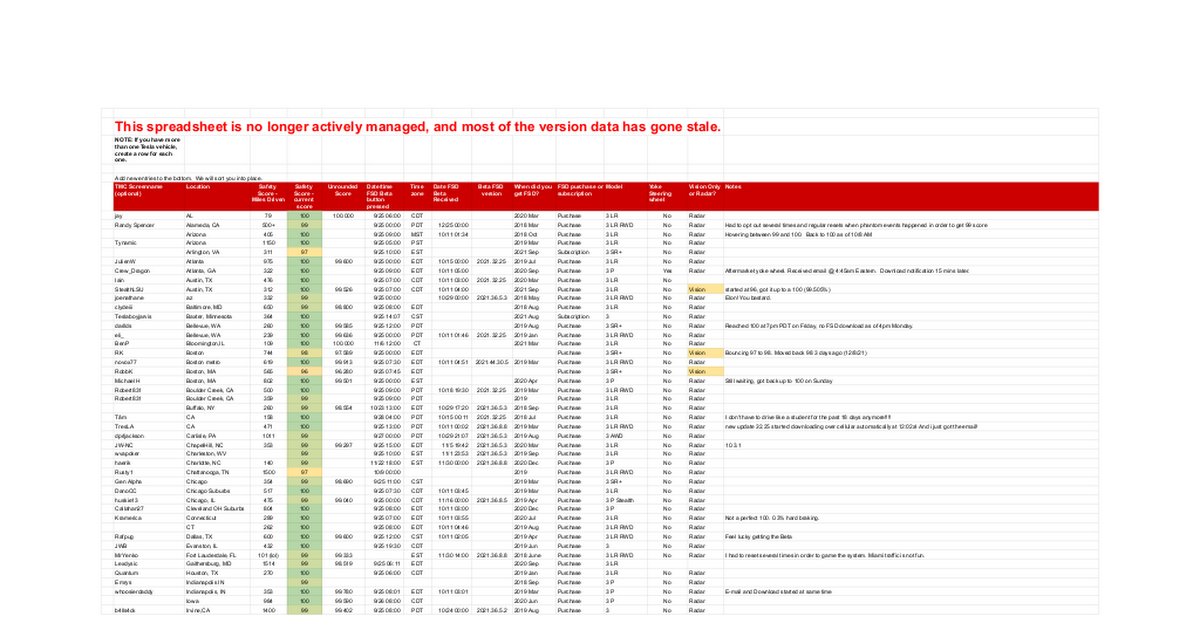
Yep. Maybe they’re smarter than people give them credit for.It's really interesting that they:
1) Came up with an "safety score" using previous data
2) That score is highly non-linear and biases everyone in the 80-100 range
3) That score weights things in a non-intuitive way
4) A score of 100 represents a collision rate lower than the average Tesla rate, yet no scores above 100 are possible
5) After a week of data, magically there are almost exactly 1000 people in the group.
Hmm, I wonder if they actually wanted something that gave them 1K "safest people" and actually created an algorithm that would to pick ~1K people if run for a week on a the data set, instead of being only focused on relative safety of drivers. For all we know it puts 1K at 100, 2K at 99, 3K at 98, etc, so it's actually just an engineered roll out under the PR of "safety."
I think the weights in the score are very intuitive. By far the biggest factor is hard braking which intuitively would be correlated with hitting things. Think about braking events as having a long tail where at the extreme you’re braking at 100% and hit something. People with that distribution shifted to the left are safer drivers.