


Welcome to Tesla Motors Club
Discuss Tesla's Model S, Model 3, Model X, Model Y, Cybertruck, Roadster and More.
Register
Install the app
How to install the app on iOS
You can install our site as a web app on your iOS device by utilizing the Add to Home Screen feature in Safari. Please see this thread for more details on this.
Note: This feature may not be available in some browsers.
-
Want to remove ads? Register an account and login to see fewer ads, and become a Supporting Member to remove almost all ads.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Artificial Intelligence
- Thread starter Buckminster
- Start date
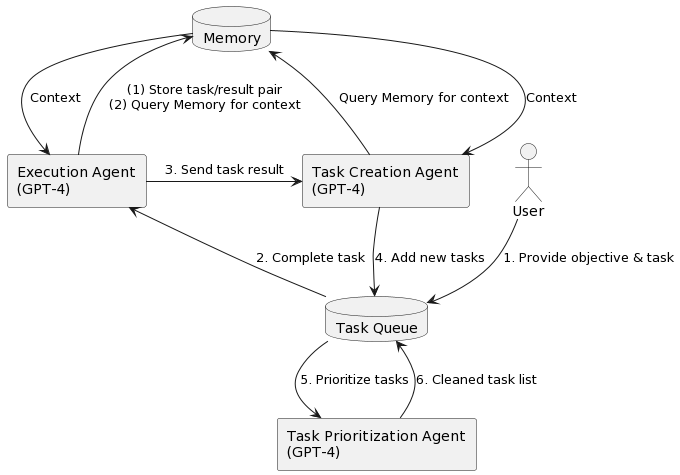
On AutoGPT - LessWrong
The primary talk of the AI world recently is about AI agents (whether or not it includes the question of whether we can’t help but notice we are all going to die.) …
 www.lesswrong.com
www.lesswrong.com
Thus, for example, we already have ChaosGPT, told explicitly to cause mayhem, sow distrust and destroy the entire human race. This should at least partially answer your question of ‘why would an AI want to destroy humanity?’ it is because humans are going to tell it to do that.
What To Expect Next
AutoGPT is brand new. What predictions can we make about this class of thing?...
- In the short term, AutoGPT and its ilk will remain severely limited. The term ‘overhyped’ will be appropriate. Improvements will not lead to either a string of major incidents or major accomplishments.
- There will still be viable use cases, even relatively soon. They will consist of relatively bounded tasks with clear subtasks that are things that such systems are already known to be good at. What AutoGPT-style things will enable will not be creative solutions, it will be more like when you would have otherwise needed to manage going through a list of tasks or options manually, and now you can automate that process, which is still pretty valuable.
- Thus, the best and most successful AutoGPT-style agents people use to do tasks will, at least for a while, be less universal, less auto, and more bounded in both goals and methods. They will largely choose from a known ‘pool of tricks’ that are known to be things they can handle, if not exclusively then primarily. There will be a lot of tinkering, restricting, manual error-checking, explicit reflection steps and so on. Many will know when to interrupt the auto and ask for human help.
- There will be a phase where there is a big impact from Microsoft Copilot 365 (and Google Bard’s version of it, if that version is any good) during which it overshadows agent LLMs and other LLM wrapping attempts. Microsoft and Google will give us ‘known to be safe’ tools and most people will, mostly wisely, stick with that for a good while.
- Agent-style logic will be incorporated into the back end of those products over time, but will be sandboxed and rendered ‘safe’ the way the current product announcements work – it will use agent logic to produce a document or other output sometimes, or to propose an action, but there will always be a ‘human in the loop’ for a good while.
- Agents, with the proper scaffolding, restrictions, guidance and so on, will indeed prove in the longer run the proper way to get automation of medium complexity tasks or especially multi-step branching tasks, and also be good to employ when doing things like (or dealing with things like) customer relations or customer service. Risk management will be a major focus.
- There will be services that help you create agents that have a better chance of doing what you want and less of a chance of screwing things up, which will mostly be done via you talking to an agent, and a host of other similar things.
- A common interface will be that you ask your chatbot (your GPT4-N or Good Bing or Bard-Y or Claude-Z variant) to do something, and it will sometimes respond by spinning up an agent, or asking if you want to do that.
- We will increasingly get used to a growing class of actions that are now considered atomic, where we can make a request directly and it will go well.
- This will be part of an increasing bifurcation between those places where such systems can be trusted and the regulations and risks of liability allow them, versus those areas where this isn’t true. Finding ways to ‘let things be messy’ will be a major source of disruption.
- It will take a while to get seriously going, but once it does there will be increasing economic pressure to deploy more and more agents and to give them more and more authority, and assign them more and more things.
- There will be pressure to increasingly take those agents ‘off the leash’ in various ways, have them prioritize accomplishing their goals and care less about morality or damage that might be done to others.
- A popular form of agent will be one that assigns you, the user, tasks to do as part of its process. Many people will increasingly let such agents plan their days.
- Prompt injections will be a major problem for AutoGPT-style agents. Anyone who does not take this problem seriously and gives their system free internet access, or lets it read their emails, will have a high probability of regretting it.
- Some people will be deeply stupid, letting us witness the results. There will be incidents of ascending orders of magnitudes of money being lit on fire. We will not always hear about them, but we’ll hear about some of them. When they involve crypto or NFTs, I will find them funny and I will laugh.
- The incidents likely will include at least one system that was deployed at scale or distributed and used widely, when it really, really shouldn’t have been.
- These systems will perform much better when we get the next generation of underlying LLMs, and with the time for refinement that comes along with that. GPT-5 versions of these systems will be much more robust, and a lot scarier.
- Whoever is doing the ARC evaluations will not have a trivial job when they are examining things worthy of the name GPT-5 or GPT-5-level.
- The most likely outcome of such tests is that ARC notices things that everyone involved would have previously said make a model something you wouldn’t release, then everyone involved says they are ‘putting in safeguards’ of some kind, changes the goal posts, and releases anyway.
- We will, by the end of 2023, have the first agent GPTs that have been meaningfully ‘set loose’ on the internet, without any mechanism available for humans to control them or shut them down. Those paying attention will realize that we don’t actually have a good way to shut the next generation of such a thing down if it goes rogue. People will be in denial about the implications, and have absolutely zero dignity about the whole thing.

Down the road, he is worried that future versions of the technology pose a threat to humanity because they often learn unexpected behavior from the vast amounts of data they analyze. This becomes an issue, he said, as individuals and companies allow A.I. systems not only to generate their own computer code but actually run that code on their own. And he fears a day when truly autonomous weapons — those killer robots — become reality.
“The idea that this stuff could actually get smarter than people — a few people believed that,” he said. “But most people thought it was way off. And I thought it was way off. I thought it was 30 to 50 years or even longer away. Obviously, I no longer think that.”
Imo this is how a singularity looks like. People keep saying that x is several decades away, then a year later it is here. Over and over again. Even the people in the field severely underestimate progress. Facebooks AI lead said that computers beating humans was a decade away a few months before Google did it.
I don't really care if AI are developing AI, or humans are using AI to better develop AI. Anyway the rate of progress is increasing and that means a singularity is happening. We should take this a lot more serious than we are doing. I'm not saying that doom is certain, just that in the singularity things are hard to predict and there are many ways things can go wrong, anyone with some creativity can see this. The stakes are very high... And I don't really see how we can stop an ASI from killing us either if the ASI wants to, ASI accidently does it or some random human tells the ASI to do it... Until we have a good solution, caution is warranted.
Basically one employee at Alphabet thinks they should opensource a lot more of their work, because Meta has been opensourcing and some of their smaller models are performing well. It's a nice argument, but I don't think Meta>OpenAI&Google just because of this argument.Lots of moat discussion on twitter due to this article:
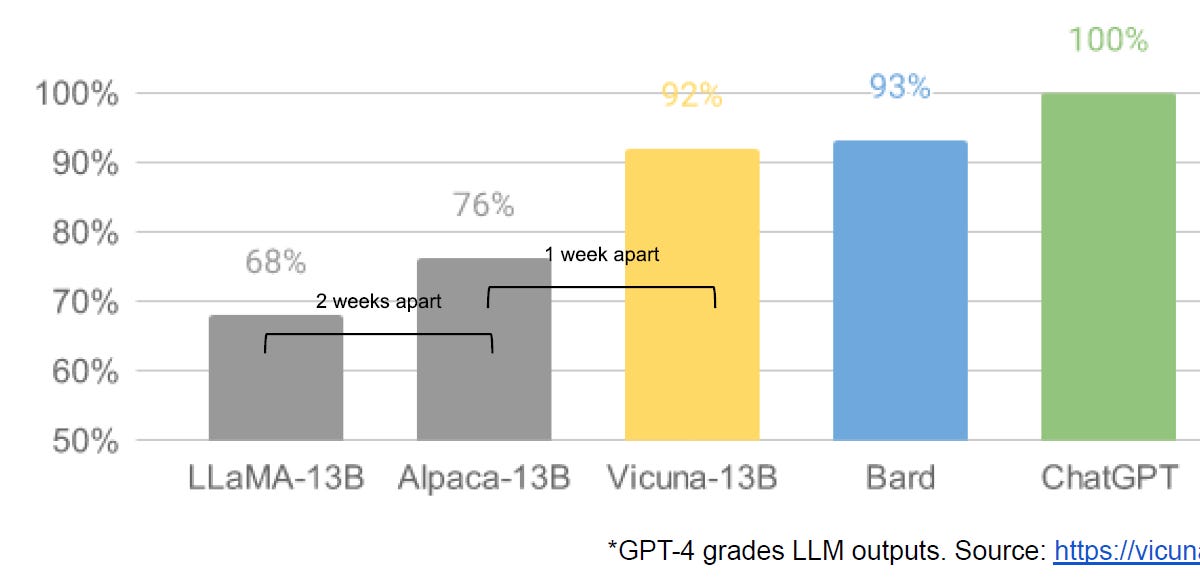
Google "We Have No Moat, And Neither Does OpenAI"
Leaked Internal Google Document Claims Open Source AI Will Outcompete Google and OpenAIwww.semianalysis.com
Fwiw I recommend this book about the history of AI, how Facebook being late to the game decided to opensource etc:
It's a fun read about how people seriously underestimated neural networks, how many experts who were sure who turned out to be wrong etc and how some small group of people such as Hinton, Alex, Ilya etc got the technology to break through 10 years ago.
Thanks for recommendation. Turns out I bought the book 2 years ago but never got around to reading it. Seems more relevant today…Basically one employee at Alphabet thinks they should opensource a lot more of their work, because Meta has been opensourcing and some of their smaller models are performing well. It's a nice argument, but I don't think Meta>OpenAI&Google just because of this argument.
Fwiw I recommend this book about the history of AI, how Facebook being late to the game decided to opensource etc:
It's a fun read about how people seriously underestimated neural networks, how many experts who were sure who turned out to be wrong etc and how some small group of people such as Hinton, Alex, Ilya etc got the technology to break through 10 years ago.
So not much bad blood?
I have a feeling that Elon told Karpathy to go on a sabbatical to OpenAI and learn about LLMs so he can come back around the time Optimus is ready and help Tesla with LLMs in it.So not much bad blood?

Andrej Karpathy says he might return to Tesla for 'Act 2' [Interview]
Tesla’s former Senior Director of Artificial Intelligence (AI) Andrej Karpathy has revealed in a new interview that he may return to Tesla to work on more than just the automaker’s self-driving software, but also their […]
 driveteslacanada.ca
driveteslacanada.ca
That would make a LOT of sense.I have a feeling that Elon told Karpathy to go on a sabbatical to OpenAI and learn about LLMs so he can come back around the time Optimus is ready and help Tesla with LLMs in it.
Andrej Karpathy says he might return to Tesla for 'Act 2' [Interview]
Tesla’s former Senior Director of Artificial Intelligence (AI) Andrej Karpathy has revealed in a new interview that he may return to Tesla to work on more than just the automaker’s self-driving software, but also their […]

Similar threads
- Replies
- 57
- Views
- 5K
- Replies
- 9
- Views
- 1K
- Replies
- 48
- Views
- 7K
- Replies
- 137
- Views
- 10K